Microsoft Azure apiでOutlookメールを読み込む
2025/06/28
- ~ index ~
- 概要
- Microsoft Azureに登録
- Device Code認証
- 感想
- 実例

概要
一旦、削除したMicrosoft OneDriveを再導入し有効利用しようとしたのがきっかけで、最近目立つフィッシングメール対策もあってメールアプリを従来のOffice製品のOutlookから新Outlookに切り替えることにした。同じOutlookの名前なので紛らわしいが、中身は全く別もの。 呼び方も従来のOutlookと新Outlookで区別している。
アイコンは新Outlook( )の上部が三角形で、従来のOutlook(
)の上部が三角形で、従来のOutlook( )は平べったい。
)は平べったい。
新Outlookは新機能がいろいろ盛り込まれており、便利と言えば便利だが、人によっては「余計な機能が増えた」と感じるかもしれない。その一方で、Microsoftアカウントのメールと従来のPOP/IMAPアカウントの扱いには明確な違いがあるようだ。
従来のOutlookに送られて来るあるメールをPythonプログラムでhtml形式に変換してサイトに掲載していたが、新Outlookでは全く仕様が異なるため、メールを読み込む方法をChatGPTとのプロンプトで体験した。
新Outlookではセキュリテイが強化されておりメールをプログラムで読み込むには、セキュリティウォールが立ちふさがっている。
今回メールを読み込むにはAzureを使用する。Azure (Microsoft Azure) は、Microsoftが提供するクラウドコンピューティングプラットフォームのこと。サーバー、ストレージ、ネットワークなどのITインフラや、IoT、AI、データ分析など、さまざまな開発・分析業務をクラウド上で実現する。基本は有料だが、今回のメール読み込みは無料で使える。
MicrosoftのAzureは、企業のイメージカラーである青を体現したサービスであり、その視覚的な統一感と信頼性の高さから、同社の中核的なクラウドサービスとして位置づけられている。
Microsoft Azureに登録
pythonでメールを取得するための必要なpython ライブラリー msal (Microsoft Authentication Library)を コマンドプロンプトで導入しておく。( pip install msal requests )
AzureとOutlookメールの関係(なぜAzureが必要?) ✅ 目的: Outlookにある自分のメールデータをプログラムから取得したい。 🔑 問題: メールは個人情報なので、勝手にアクセスできないように強く守られている。 そのため Microsoft は「Microsoft Graph API」という安全な通路(API)を用意している。
| Azureの機能 | 説明 |
|---|---|
| ☁️ Azure AD(Entra ID) | アプリの認証と許可(誰がアクセスするのか)を管理する。 *Azure ADはMicrosoft Entra IDに名称変更された。 |
| 🪪 アプリ登録(App Registration) | 「このプログラムは安全ですよ」と Microsoft に申請する。IDと秘密鍵を取得する。 |
| 🔐 APIの権限設定 | たとえば「Mail.Read」など、どのデータにアクセスしてよいかを明示する。 |
まずは、Azureポータル にMicrosoftアカウントでログオン

Azureポータル 「Microsoft Entra ID」(図は登録済みの画像)
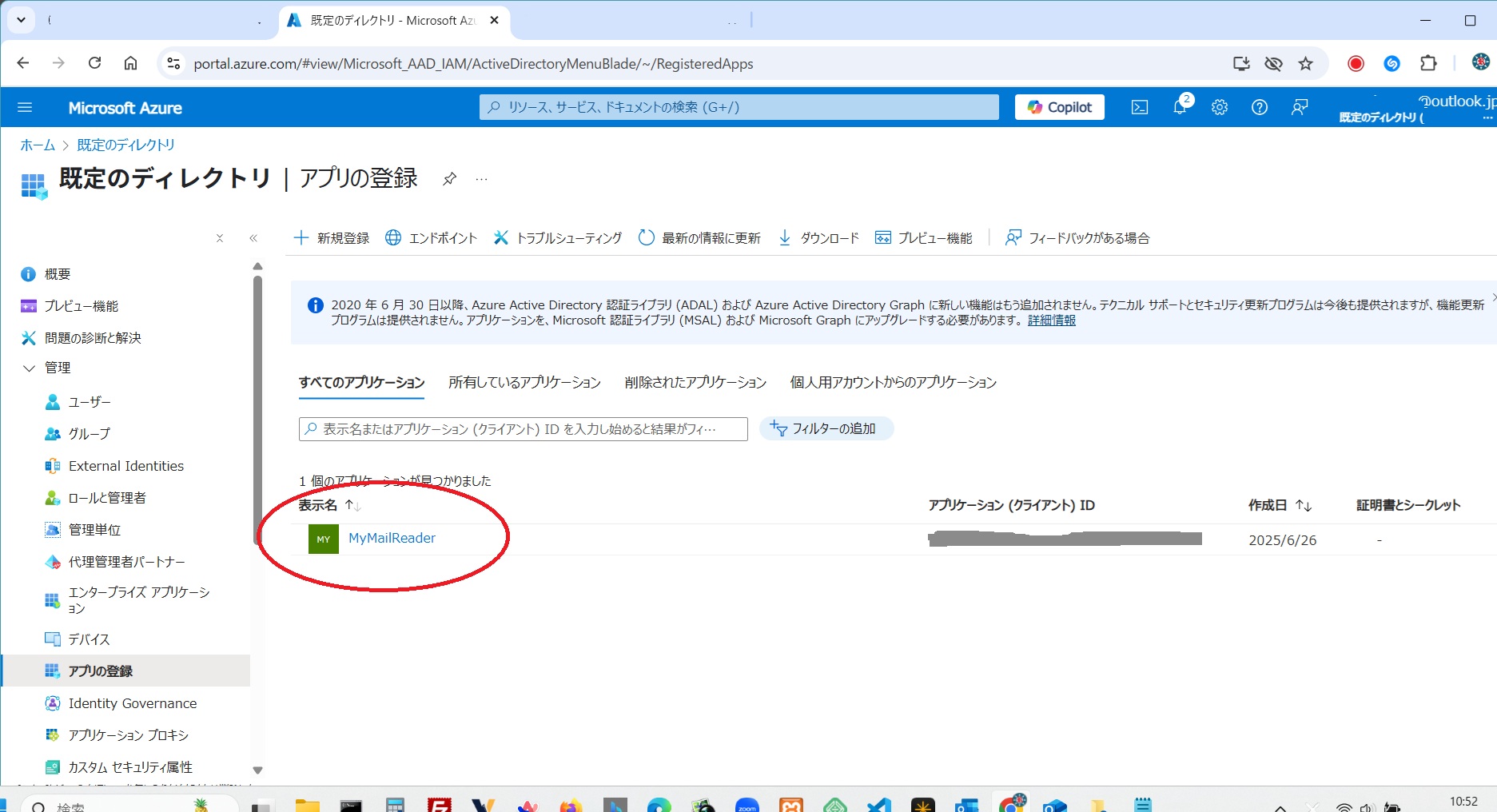
アプリの登録 +新規登録 > アプリの登録(図は登録済みの画像)


アクセス許可の要求

「アプリの登録」、「すべてのアプリケーション」、「アプリケーション名をクリック」
Device Code認証
Device Code 認証とは、ユーザー本人が、今使っているプログラムに「私はこのアカウントの持ち主です」と証明するための手続き。Microsoftアカウントとアプリケーション(Client ID)の組み合わせで認証される。
Device Code認証 py コード
import msal, json CLIENT_ID = "39a6def2-e899-4031-9847-42988ba9d9e2" TENANT_ID = "consumers" # ←個人アカウントならこれ SCOPES = ["Mail.Read"] app = msal.PublicClientApplication( CLIENT_ID, authority=f"https://login.Microsoftonline.com/{TENANT_ID}" ) flow = app.initiate_device_flow(scopes=SCOPES) if "error" in flow: raise RuntimeError(json.dumps(flow, indent=2)) print(flow["message"]) # ← ここでコードと URL が出るはず result = app.acquire_token_by_device_flow(flow) print(result["access_token"][:40], "...")
- TENANT_ID = "consumers" は、Microsoft アカウント(個人用アカウント) のユーザー(@outlook.com, @hotmail.com, @live.jp など)を対象とした認証用の特別なテナント指定。個人ユーザー向けログインに限定したい場合に使う。
- flow = app.initiate_device_flow(scopes=SCOPES)
デバイス認証フロー(Device Code Flow)を開始。この時点で、ユーザーが 「ブラウザで特定のURLにアクセスし、表示されたコードを入力する」ように促される。
ターミナル出力
To sign in, use a web browser to open the page https://www.Microsoft.com/link and enter the code ABCDEFGH to authenticate.
https://www.Microsoft.com/linkにリンクし ABCDEFGH を入力する
感想
以前のPOP/IMAPメールのときにPythonコードでhtml作成プログラムを作ったので、新Outlookのクラウド上のメールの読み込み方に挑戦してみた。結構面倒と感じた。
実例
Python、htmlの例 : キャッシュ認証(2度目以降)、添付画像保存、HTML(画像含む)作成
フォルダー構成 ├─ img_in/ ← 自動生成 ├─ html/ ← HTML出力先 ├─ text/ │ ├─ text_1.txt ← HTML上部テンプレート │ └─ text_2.txt ← HTML下部テンプレート ├─ token_cache.bin ← トークンキャッシュ(自動生成)
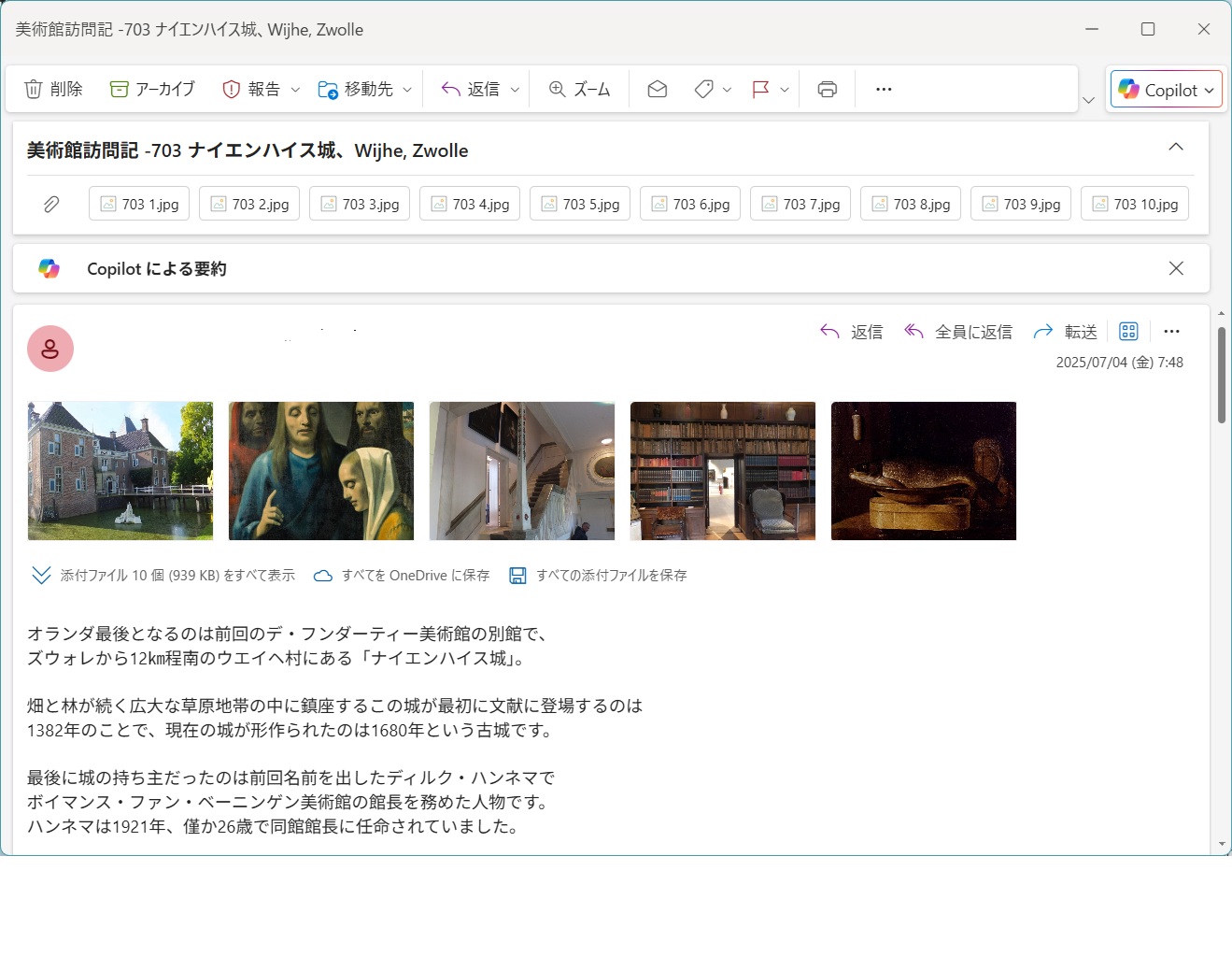
outlookメール
メールを読み込むpythonプログラム
# ======= Create html code from outlook email ====== import os import requests import re import base64 import cv2 import pandas as pd from bs4 import BeautifulSoup from natsort import natsorted from msal import PublicClientApplication, SerializableTokenCache from datetime import datetime, timedelta # === Azure認証設定 === CLIENT_ID = "39a6def2-e899-4031-9847-42988ba9d9e2" TENANT_ID = "consumers" AUTHORITY = f"https://login.microsoftonline.com/{TENANT_ID}" SCOPES = ["https://graph.microsoft.com/Mail.Read"] FOLDER_NAME = "長野美術館" MANUAL_DATE = "2025-07-04" # === トークンキャッシュ処理 === cache = SerializableTokenCache() cache_file = "token_cache.bin" if os.path.exists(cache_file): with open(cache_file, "rb") as f: cache.deserialize(f.read()) app = PublicClientApplication(CLIENT_ID, authority=AUTHORITY, token_cache=cache) accounts = app.get_accounts() if accounts: result = app.acquire_token_silent(SCOPES, account=accounts[0]) if not result: print("🔄 キャッシュのトークンが無効。再認証を開始します。") flow = app.initiate_device_flow(scopes=SCOPES) print(flow["message"]) result = app.acquire_token_by_device_flow(flow) if not result or "access_token" not in result: raise Exception("❌ アクセストークンの取得に失敗しました。") if cache.has_state_changed: with open(cache_file, "wb") as f: f.write(cache.serialize().encode("utf-8")) headers = {"Authorization": f"Bearer {result['access_token']}"} # === メールフォルダの取得 === folders = requests.get("https://graph.microsoft.com/v1.0/me/mailFolders", headers=headers).json() # === フォルダID取得(ページネーション+サブフォルダ対応) === def get_folders_recursive(url): folders = [] while url: res = requests.get(url, headers=headers) res.raise_for_status() data = res.json() folders.extend(data.get("value", [])) url = data.get("@odata.nextLink") return folders def find_folder_id_recursive(folder_name, parent_id=""): if parent_id: url = f"https://graph.microsoft.com/v1.0/me/mailFolders/{parent_id}/childFolders" else: url = "https://graph.microsoft.com/v1.0/me/mailFolders" folders = get_folders_recursive(url) for folder in folders: print("📂", folder["displayName"]) # 表示されるフォルダー確認用 if folder["displayName"] == folder_name: return folder["id"] sub_id = find_folder_id_recursive(folder_name, folder["id"]) if sub_id: return sub_id return None # === フォルダIDの取得(長野美術館) === folder_id = find_folder_id_recursive(FOLDER_NAME) if not folder_id: raise Exception("指定フォルダが見つかりません") # === メール取得(フィルタ付き) === # JST → UTCに変換(9時間引く) jst_datetime = datetime.strptime(MANUAL_DATE, "%Y-%m-%d") - timedelta(hours=9) utc_date_str = jst_datetime.strftime("%Y-%m-%dT%H:%M:%SZ") # URLに組み込む url = f"https://graph.microsoft.com/v1.0/me/mailFolders/{folder_id}/messages" url += f"?$filter=receivedDateTime ge {utc_date_str}&$orderby=receivedDateTime desc&$top=10" print(url) messages = requests.get(url, headers=headers).json().get("value", []) if not messages: raise Exception("メールが見つかりません") msg = messages[0] subject = msg["subject"] html_body = msg["body"]["content"] # === 本文HTMLクリーニング関数群 === def clean_outlook_html(html): html = html.replace("<br><br>", "\n\n").replace("<br>", "\n") soup = BeautifulSoup(html, "html.parser") for tag in soup(["style", "meta", "link", "script"]): tag.decompose() for font in soup.find_all("font"): font.unwrap() for tag in soup.find_all(True): tag.attrs = {k: v for k, v in tag.attrs.items() if k.lower() not in ['style', 'face', 'color', 'size']} return soup.get_text() def remove_header_lines(text): import re lines = text.splitlines() output = [] for line in lines: # 件名を含む行に本文が続くパターンを処理 if line.startswith("件名:"): print("DEBUG 行内容:", line) match = re.search(r"件名:\s*(.*?)\s{2,}(.*)", line) print("DEBUG マッチ結果:", match) if match: # 本文のみを抽出(group(2)) output.append(match.group(2).strip()) continue # その他の差出人や送信日時は除外 if line.startswith("差出人:") or line.startswith("送信日時:"): continue output.append(line) return "\n".join(output) def format_paragraphs(text): lines = text.strip().splitlines() paragraphs = [] current = [] for line in lines: line = line.strip() if line == "": if current: paragraphs.append("<p>" + " ".join(current).strip() + "</p>") current = [] else: current.append(line) if current: paragraphs.append("<p>" + " ".join(current).strip() + "</p>") return paragraphs # === 本文整形実行 === cleaned_text = clean_outlook_html(html_body) cleaned_text = remove_header_lines(cleaned_text) # === 添付画像保存 === img_dir = "img_in" if os.path.exists(img_dir): for f in os.listdir(img_dir): os.remove(os.path.join(img_dir, f)) os.rmdir(img_dir) os.makedirs(img_dir) attachments_url = f"https://graph.microsoft.com/v1.0/me/messages/{msg['id']}/attachments" attachments = requests.get(attachments_url, headers=headers).json().get("value", []) for att in attachments: if "contentBytes" in att and att["contentType"].startswith("image/"): fname = att["name"] bdata = base64.b64decode(att["contentBytes"]) with open(os.path.join(img_dir, fname), "wb") as f: f.write(bdata) # === HTML出力構成 === title_num = re.sub("\\D", "", subject) html_path = f"html/nagano_art_{title_num}.html" o_file = 'img16' with open("text/text_1.txt", encoding="utf-8") as f1, open(html_path, "w", encoding="utf-8") as out: for line in f1: if "<title>" in line: line = f"<title>{subject}</title>\n" if "<h2>" in line: line = f'<h2><span id="spand">{subject}</span></h2>\n' out.write(line) img_files = natsorted(os.listdir(img_dir)) body_lines = cleaned_text.splitlines() comments = [l.replace('作', '作<br>') for l in body_lines if '添付' in l and ':' in l] with open(html_path, "a", encoding="utf-8") as out: for i, fname in enumerate(img_files): im = cv2.imread(os.path.join(img_dir, fname)) tag = '<div id="photo2">' if im.shape[0] > im.shape[1]: tag = '<div id="photo1">' elif im.shape[1] / im.shape[0] > 1.5: tag = '<div id="photo3">' comment = comments[i] if i < len(comments) else "" out.write(f'{tag}<a href="javascript:;" onclick="OPEN1(\'{o_file}/{fname}\')"><img src="{o_file}/{fname}"></img></a><p>{comment}</p></div>\n') out.write('\n</div>\n<div id="divtext">\n') for p in format_paragraphs(cleaned_text): if '添付' in p and ':' in p: # end break out.write(p + '\n') out.write('</div>\n') with open("text/text_2.txt", encoding="utf-8") as f2, open(html_path, "a", encoding="utf-8") as out: next_n = int(title_num) + 1 for line in f2: if '<div id="divnextpage">' in line: line = f'<div id="divnextpage"><a href="nagano_art_{next_n}.html"><p>美術館訪問記 No.{next_n}はこちら</p></a></div>\n' out.write(line) print(f"✅ HTML生成完了: {html_path}")
- 最初のアクセス認証はマニュアル入力しキャッシュに保管、2回目以降はキャッシュからのコードで認証。Microsoftアカウントやパスワード変更の場合は再度マニュアル入力する必要がある
- ターゲットフォルダーはサブフォルダーまで探す
- ターゲットメールは指定した送信日時のもの。クラウドではUTC(協定世界時)になっているためJST → UTCに変換(9時間引く)
- メール本体の1行目は[件名: ]に本文の1行目が同じラインにあるため、[件名: ]を分離する
- 横長画像(landscape)と縦長画像(portrait)を区別し、<div id="photo1">と <div id="photo2">でwidthを変える。
生成されたhtml。WEB掲載では絵画画像の著作権の有無を調べて調整する。
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <meta name="viewport" content="width=device-width,initial-scale=1.0"> <meta http-equiv="Content-Script-Type" content="text/javascript"> <title>美術館訪問記 -703 ナイエンハイス城、Wijhe, Zwolle</title> <link rel="stylesheet" type="text/css" href="naganoart.css"> <style type="text/css"> <!-- --> </style> <script type="text/javascript" src="nagano.js"></script> </head> <body> <div id="div0"> <div id="modoru"><a href="index.html"><p>戻る</p></a></div> <div id="div01"> <a name="page top"></a> <div id="divheader"> <h2><span id="spand">美術館訪問記 -703 ナイエンハイス城、Wijhe, Zwolle</span></h2> </div> <div style="clear:both;"></div> <h5 style="text-align:right;">(* 長野一隆氏メールより。写真画像クリックで原寸表示されます。)</h5> <div id="divphoto"><div id="photo3"><a href="javascript:;" onclick="OPEN1('img16/703 1.jpg')"><img src="img16/703 1.jpg"></img></a><p>添付1:ナイエンハイス城</p></div> <div id="photo1"><a href="javascript:;" onclick="OPEN1('img16/703 2.jpg')"><img src="img16/703 2.jpg"></img></a><p>添付2:ハン・ファン・メーヘレン作<br>「キリストと姦婦」</p></div> <div id="photo3"><a href="javascript:;" onclick="OPEN1('img16/703 3.jpg')"><img src="img16/703 3.jpg"></img></a><p>添付3:ナイエンハイス城内部</p></div> <div id="photo3"><a href="javascript:;" onclick="OPEN1('img16/703 4.jpg')"><img src="img16/703 4.jpg"></img></a><p>添付4:ディルク・ハンネマの書斎</p></div> <div id="photo2"><a href="javascript:;" onclick="OPEN1('img16/703 5.jpg')"><img src="img16/703 5.jpg"></img></a><p>添付5:ストスコップフ作<br>「皿の上の鯉のある静物」</p></div> <div id="photo2"><a href="javascript:;" onclick="OPEN1('img16/703 6.jpg')"><img src="img16/703 6.jpg"></img></a><p>添付6:スナイデルス作<br>「狩猟戦利品と茹でたロブスターのある静物」</p></div> <div id="photo2"><a href="javascript:;" onclick="OPEN1('img16/703 7.jpg')"><img src="img16/703 7.jpg"></img></a><p>添付7:ヤン・スライテルス作<br>「窓敷居の上の花々」</p></div> <div id="photo1"><a href="javascript:;" onclick="OPEN1('img16/703 8.jpg')"><img src="img16/703 8.jpg"></img></a><p>添付8:パウル・シトロエン作<br>「18歳の自画像」1914年</p></div> <div id="photo1"><a href="javascript:;" onclick="OPEN1('img16/703 9.jpg')"><img src="img16/703 9.jpg"></img></a><p>添付9:パウル・シトロエン作<br>「コリー・ミューレンフェルトの肖像」1939年</p></div> <div id="photo3"><a href="javascript:;" onclick="OPEN1('img16/703 10.jpg')"><img src="img16/703 10.jpg"></img></a><p>添付10:ナイエンハイス城野外彫刻庭園</p></div> </div> <div id="divtext"> <p>オランダ最後となるのは前回のデ・フンダーティー美術館の別館で、 ズウォレから12㎞程南のウエイヘ村にある「ナイエンハイス城」。</p> <p>畑と林が続く広大な草原地帯の中に鎮座するこの城が最初に文献に登場するのは 1382年のことで、現在の城が形作られたのは1680年という古城です。</p> <p>最後に城の持ち主だったのは前回名前を出したディルク・ハンネマで ボイマンス・ファン・ベーニンゲン美術館の館長を務めた人物です。 ハンネマは1921年、僅か26歳で同館館長に任命されていました。</p> <p>彼は1958年から死亡する1984年までこの城に居住していましたが、 土地や城に併せて自分の膨大な美術コレクションごと彼が設立した ハンネマ=デ・ストルアス財団に寄贈していました。デ・フンダーティー美術館も この財団の持ち物で、一部はこの一帯を管轄している州の所管になっています。</p> <p>デ・フンダーティー美術館の別館とはいえ、展示面積はこちらの方が広く、 興味深い作品も多く展示されています。ただ車でしか来られないことも起因して いるのでしょうが、日本語のインターネット上での検索結果は皆無でした。</p> <p>ディルク・ハンネマは両親が富裕だったこともあり、若年時から美術収集を 開始していますが、個人でこれだけのコレクションを形成したのは驚きです。 これら以外にもボイマンス・ファン・ベーニンゲン美術館にも 個人的に数多くの作品を寄贈しているのですから、なおさらです。</p> <p>ハン・ファン・メーヘレンのフェルメールの贋作で味噌をつけたのは気の毒ですが、 近所付き合いがあり彼の幼年時から美術の師と仰いだアブラハム・ブレディウスの お墨付きに基づいての判断だったのですから、同情の余地は大いにあります。</p> <p>この城にもハンネマ自身がフェルメール作と信じて購入したメーヘレン作の 「キリストと姦婦」が展示されていました。</p> <p>内部は昔からの居城らしく、狭い部屋が数多くあり、導線も複雑ですが、 ディルク・ハンネマが使用していた立派な書斎も残されていました。</p> <p>この城の最大の見ものはストスコップフの「皿の上の鯉のある静物」。 彼の作品はどれもまるで封印された時間を紐解くような、重厚な存在感、 永遠不変の時の流れ、悠久性を感じさせてくれます。</p> <p>静物画と言えば、静物画家から転じて最初期の専門の動物画家として活躍した フランス・スナイデルスの「狩猟戦利品と茹でたロブスターのある静物」が 彼の両方の専門性を生かした絵画として面白い。</p> <p>オランダ近代絵画を代表する画家ヤン・スライテルスの作品は5点ありましたが、 その中から「窓敷居の上の花々」を添付しましょう。</p> <p>展示作品数で最も多かったのはパウル・シトロエンの15点。</p> <p>パウル・シトロエンは1896年、ベルリン生まれのユダヤ系オランダ人で、 1919年に創立されたばかりのバウハウスでパウル・クレーやカンディンスキーの 下で学び、卒業後は絵画や写真、オランダの切手のデザインなどで有名になります。</p> <p>1933年にはアムステルダムにバウハウスと同様な教育を行うことを目指した ニューアート・アカデミーを共同創設者として立ち上げますが、4年で閉鎖。</p> <p>1937年からはハーグの美術学校教師として多くの生徒を育てています。 1942年にはナチスのユダヤ人迫害を避けて友人宅のシェルターで一時隠蔽生活を 強いられています。1960年に退任し、その後は数多くの肖像画を描いて 暮らしました。1983年ハーグ郊外のヴァッセナールで死去。</p> <p>ズウォレが州都であるオランダの州オーバーアイセルの議員がシトロエンの親友で、 彼の推薦で同州は1973年から1975年にかけてパウル・シトロエン作品を 2000点以上も購入し、その一部がこの城に展示されているのでした。</p> <p>なおコリー・ミューレンフェルトはハーグ美術学校でシトロエンの生徒でした。</p> <p>この城には現代彫刻専門の野外彫刻庭園も付属しています。展示されている彫刻は ディルク・ハンネマの収集品に財団購入品が付け加えられたものです。</p> </div> <div style="clear:both;"></div> <!-- <div id="divtext2"> <p> (添付4:パブロ・ピカソ作「鳩のある静物」、添付5:アントニオ・ロペス・ガルシア作「フランシスコ・カレテロ」、添付6:鴨居羊子作「さようなら」 および 添付7:鴨居玲作 「自画像(パレット)」は著作権上の理由により割愛しました。 <br> 長野さんから直接メール配信を希望される方は、トップページ右上の「メール配信登録」をご利用下さい。管理人) </p> </div> --> <!-- <div id="divnextpage"><a href="nagano_art_704.html"><p>美術館訪問記 No.704はこちら</p></a></div> --> <div id="modoru"><a href="index.html"><p>戻る</p></a></div> <br> <br> <!-- access counter --!> <table id="tableac2"> <tr><td><img src="daycount2/daycount.cgi?gif"></td><td><img src="daycount2/daycount.cgi?today"></td><td><img src="daycount2/daycount.cgi?yes"></td></tr> </table> <br> </div> <div id="divtrailer2"><p><script type="text/JavaScript"> <!-- now = new Date(); str = "©"+ now.getFullYear()+" * 長野氏の美術館訪問記 * All rights reserved."; document.write(str); --> </script></p></div> </div> </body> </html>